Windows 下 Python 统一字符编码
背景说明
在尝试从源码安装某个 PyPi 库时,Windows 下报错——提示 UnicodeDecodeError,这个错误在 Linux 测试没有出现过。然而甲方的技术栈,无论是软件,还是机器,都依赖微软系,这就倒逼我们去适配他们的环境。
问题分析
虽然 PyPi 有这个包的 wheel,但是更新没有那么频繁。所以,官方推荐将代码 Clone 下来,再通过 setup.py 来构建并安装。
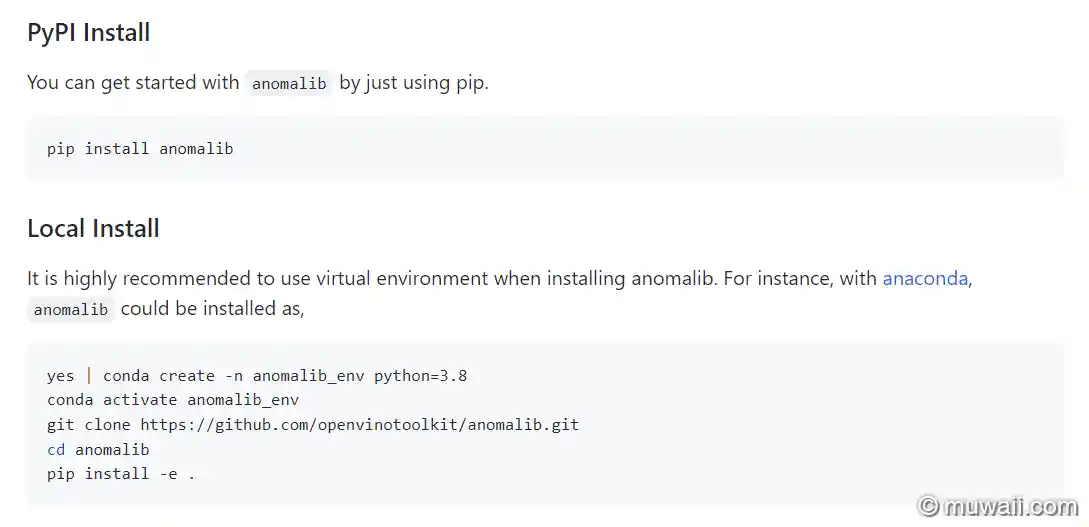
图 1: 安装时报错
报错细节
(anomalib_env) E:\Projects\_xxxxx.com\anomalib>pip install e .
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Processing e:\projects\_xxxxx.com\anomalib
Installing build dependencies ... done
Getting requirements to build wheel ... error
ERROR: Command errored out with exit status 1:
command: 'E:\ProgramData\conda\envs\anomalib_env\python.exe' 'E:\ProgramData\conda\envs\anomalib_env\lib\site-packages\pip\_vendor\pep517\in_process\_in_process.py' get_requires_for_build_wheel 'F:\Users\xxxxx\AppData\Local\Temp\tmpyjdcojp9'
cwd: F:\Users\xxxxx\AppData\Local\Temp\pip-req-build-0ugyr7at
Complete output (18 lines):
Traceback (most recent call last):
File "E:\ProgramData\conda\envs\anomalib_env\lib\site-packages\pip\_vendor\pep517\in_process\_in_process.py", line 349, in <module>
main()
File "E:\ProgramData\conda\envs\anomalib_env\lib\site-packages\pip\_vendor\pep517\in_process\_in_process.py", line 331, in main
json_out['return_val'] = hook(**hook_input['kwargs'])
File "E:\ProgramData\conda\envs\anomalib_env\lib\site-packages\pip\_vendor\pep517\in_process\_in_process.py", line 117, in get_requires_for_build_wheel
return hook(config_settings)
File "F:\Users\xxxxx\AppData\Local\Temp\pip-build-env-pmxa9i1y\overlay\Lib\site-packages\setuptools\build_meta.py", line 177, in get_requires_for_build_wheel
return self._get_build_requires(
File "F:\Users\xxxxx\AppData\Local\Temp\pip-build-env-pmxa9i1y\overlay\Lib\site-packages\setuptools\build_meta.py", line 159, in _get_build_requires
self.run_setup()
File "F:\Users\xxxxx\AppData\Local\Temp\pip-build-env-pmxa9i1y\overlay\Lib\site-packages\setuptools\build_meta.py", line 174, in run_setup
exec(compile(code, __file__, 'exec'), locals())
File "setup.py", line 91, in <module>
LONG_DESCRIPTION = (Path(__file__).parent / "README.md").read_text()
File "E:\ProgramData\conda\envs\anomalib_env\lib\pathlib.py", line 1237, in read_text
return f.read()
UnicodeDecodeError: 'gbk' codec can't decode byte 0xa2 in position 234: illegal multibyte sequence
----------------------------------------
WARNING: Discarding file:///E:/Projects/_xxxxx.com/anomalib. Command errored out with exit status 1: 'E:\ProgramData\conda\envs\anomalib_env\python.exe' 'E:\ProgramData\conda\envs\anomalib_env\lib\site-packages\pip\_vendor\pep517\in_process\_in_process.py' get_requires_for_build_wheel 'F:\Users\xxxxx\AppData\Local\Temp\tmpyjdcojp9' Check the logs for full command output.
ERROR: Command errored out with exit status 1: 'E:\ProgramData\conda\envs\anomalib_env\python.exe' 'E:\ProgramData\conda\envs\anomalib_env\lib\site-packages\pip\_vendor\pep517\in_process\_in_process.py' get_requires_for_build_wheel 'F:\Users\xxxxx\AppData\Local\Temp\tmpyjdcojp9' Check the logs for full command output.其中比较关键的错误栈是这一段:
File "F:\Users\xxxxx\AppData\Local\Temp\pip-build-env-pmxa9i1y\overlay\Lib\site-packages\setuptools\build_meta.py", line 159, in _get_build_requires
self.run_setup()
File "F:\Users\xxxxx\AppData\Local\Temp\pip-build-env-pmxa9i1y\overlay\Lib\site-packages\setuptools\build_meta.py", line 174, in run_setup
exec(compile(code, __file__, 'exec'), locals())
File "setup.py", line 91, in <module>
LONG_DESCRIPTION = (Path(__file__).parent / "README.md").read_text()
File "E:\ProgramData\conda\envs\anomalib_env\lib\pathlib.py", line 1237, in read_text
return f.read()
UnicodeDecodeError: 'gbk' codec can't decode byte 0xa2 in position 234: illegal multibyte sequence打包工具会读取待安装库根目录下的 README.md,获取库的描述信息。其中 read_text 函数的定义如下,可以看到调用 read_text 是没有传递 encoding 这个实参的。由于 Linux 默认的编码即为 `UTF-8,这个小疏漏不会影响到后续的流程。
def read_text(self, encoding=None, errors=None):
"""
Open the file in text mode, read it, and close the file.
"""
encoding = io.text_encoding(encoding)
with self.open(mode='r', encoding=encoding, errors=errors) as f:
return f.read()但是 Windows 系统用户区域使用的字符编码可能与文件的字符编码不一致,比如在笔者电脑区域编码是 GBK,而文件编码一般来说是 UTF-8。如果该文件中包含非 ASCII 字符(比如中日韩,或者 emoji 表情符号),那么读取失败,进而导致 setup.py 构建失败。
想要详细了解整体的打包流程,可参考: the packaging tutorial in the packaging.python.org
临时解法
- 修改
setup.py的脚本,在 read_text() 时,显式传递encoding参数。虽然可行,但是我们不清楚库代码中有多少处这样的文件读取函数,不可能处处都手动修改。 - Python 预留了一个启动时的 Hook——pythonstartup
- 在用户目录下,创建一个 .pyhonstartup 文件
- 设置环境变量
set PYTHONSTARTUP=%USERPROFILE%/.pythonstartup - 添加如下代码,重载加载 sys,并设置默认编码
import sys
# sys.setdefaultencoding() does not exist, here!
# for Python 3.4+: reload() is in the importlib library, you need import it first
reload(sys) # Reload does the trick!
sys.setdefaultencoding('UTF8')第二种方法,总体上是可行的,但是就是比较 Dirty,不够优雅。
优雅解法
通过 PEP 540 增强提案[^1]可知,早在 Python 3.7 版本中,Victor Stinner 提出了一个全新的 UTF-8 模式。当 UTF-8 模式激活时,Python 表现如下:
- 全局使用 UTF-8 编码,无论当前系统平台所用的区域字符编号是什么
- 改变标准输入
stdin和标准输出stdout上的错误 handler 为surrogateescape
第一点比较好理解,就是强制使用 UTF-8 作为标准编码;第二点就有点不知所以然,下以小节进行详细解释,熟悉背后原理的读者可跳过。
Error Handlers
翻开 Error Handlers 文档,其原文是这样的,分为 8 种 Handler,其中五种为通用的,两种只能在编码时才能使用,最后一种仅限于特定的字符编码集:
strict
'strict': Raise UnicodeError (or a subclass), this is the default. Implemented in strict_errors().
严格模式,顾名思义,遇到不能编码/解码的字符直接抛出异常。这也是默认采用的处理模式。
# `UTF-8` 编码无法解码
>>> b"\xc3\xef".decode("utf-8")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc3 in position 0: invalid continuation byteignore
'ignore': Ignore the malformed data and continue without further notice. Implemented in ignore_errors().
简单忽略无效编码的字符,最后返回的结果不包含这些字符。
>>> b"\xc3\xef".decode("utf-8", errors="ignore")
''backslashreplace
'backslashreplace': Replace with backslashed escape sequences. On encoding, use hexadecimal form of Unicode code point with formats
\\xhh\\uxxxx\\Uxxxxxxxx. On decoding, use hexadecimal form of byte value with format\\xhh. Implemented in backslashreplace_errors().
某种意义上,保留了原始的字符串,并且包含了转义符的字面量形式(形如 \\xhh),如果需要将解码后的字符串转回字节数据,使用 bytearray.fromhex 可以很方便地恢复原貌。
>>> "\xc3\xef".encode("ascii", errors="backslashreplace")
b'\\xc3\\xef'
>>> b"\xc3\xef".decode("utf-8", errors="backslashreplace")
'\\xc3\\xef'
>>> c = _
>>> len(c)
8
>>> bytes(bytearray.fromhex(c.replace("\\x", "")))
b'\xc3\xef'需要注意的是,\x 和 \\x 含义是不一样,前者是转义符,后面必须要紧跟被转义的字符。而后者仅仅是字符串,不对后面的字符做任何处理,也可不跟字符。
>>> '\x'
File "<stdin>", line 1
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 0-1: truncated \xXX escape
>>> '\\x'
'\\x'replace
'replace': Replace with a suitable replacement marker; Python will use the official U+FFFD REPLACEMENT CHARACTER for the built-in codecs on decoding, and ‘?’ on encoding. Implemented in replace_errors().
这意味着,使用 replace(替换),解码时任何有问题的字节都将被替换为相同的 u+fffd 替换字符 �;在编码时,问题字符会被替换成一个问号 ?。这种转换方式的好处是你可以得到格式有效的 unicode 字符,但是会丢失文件的原始内容。以 b"\xc3\xef" 举例:
# 修改 errors handler,将无效字符替换成 \ufffd
>>> b"\xc3\xef".decode("utf-8", errors="replace")
'��'
>>> for c in _:
... print(hex(ord(c)))
...
0xfffd
0xfffdsurrogateescape
'surrogateescape': On decoding, replace byte with individual surrogate code ranging from U+DC80 to U+DCFF. This code will then be turned back into the same byte when the 'surrogateescape' error handler is used when encoding the data. (See PEP 383 [^2]for more.)
而使用 surrogateescape(代理/转义),每个字节将被替换为不同的值。例如,\xea 将被 \udcea 替换,\xf6 替换为 \udcf8。也就是说你可以知道原始字节,即再次调用 .encode(errors="surrogateescape") 就能重新得到原文。缺点是 unicode 字符串格式不正确,因为它里面包含原始代理代码(surrogate code)。依然以 b"\xc3\xef" 为例:
>>> b"\xc3\xef".decode("utf-8")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc3 in position 0: invalid continuation byte
# 修改 errors handler,在保留原始字节数据的基础上,添加 \udc 前缀
>>> b"\xc3\xef".decode("utf-8", errors="surrogateescape")
'\udcc3\udcef'
# 一样 errors handler, 再调用一次 encode,得到原始字节数据
>>> _.encode("utf-8", errors="surrogateescape")
b'\xc3\xef'xmlcharrefreplace
'xmlcharrefreplace': Replace with XML/HTML numeric character reference, which is a decimal form of Unicode code point with format
&#num;Implemented in xmlcharrefreplace_errors().
Note: only applicable to encoding (within text encodings).
此 handler 只在字符编码时可用,replace 处理方式的变种。其本意就是将超出编码表示范围的字符,替换成 &#数字; 的形式,里面的数字就是十六进制转成十进制后的数值。
>>> "Hello, 世界".encode("ascii", errors="xmlcharrefreplace")
b'Hello, 世界'
>>> for c in "世界":
... print(ord(c), hex(ord(c)))
...
19990 0x4e16
30028 0x754cnamereplace
'namereplace': Replace with \N{...} escape sequences, what appears in the braces is the Name property from Unicode Character Database. Implemented in namereplace_errors().
此 handler 只在字符编码时可用,也是 replace 处理方式的变种。替换形式是 \N{...},花括号里面是该字符中 Unicode 统一字符编码数据库中的名字。比如 ♥ 是 BLACK HEART SUIT 意指扑克牌中黑桃。
>>> "Hello, 世界".encode("ascii", errors="namereplace")
b'Hello, \\N{CJK UNIFIED IDEOGRAPH-4E16}\\N{CJK UNIFIED IDEOGRAPH-754C}'
>>> "Hello,안녕하세요".encode("ascii", errors="namereplace")
b'Hello,\\N{HANGUL SYLLABLE AN}\\N{HANGUL SYLLABLE NYEONG}\\N{HANGUL SYLLABLE HA}\\N{HANGUL SYLLABLE SE}\\N{HANGUL SYLLABLE YO}'
>>> "Hello, こんにちは".encode("ascii", errors="namereplace")
b'Hello, \\N{HIRAGANA LETTER KO}\\N{HIRAGANA LETTER N}\\N{HIRAGANA LETTER NI}\\N{HIRAGANA LETTER TI}\\N{HIRAGANA LETTER HA}'
>>> "Hello, ♥✅".encode("ascii", errors="namereplace")
b'Hello, \\N{BLACK HEART SUIT}\\N{WHITE HEAVY CHECK MARK}'surrogatepass
'surrogatepass': Allow encoding and decoding surrogate code point (
U+D800-U+DFFF) as normal code point. Otherwise these codecs treat the presence of surrogate code point in str as an error.
only specific to the given codecs: utf-8, utf-16, utf-32, utf-16-be, utf-16-le, utf-32-be, utf-32-le.
最后是比较少见的处理方式,它只适用于特定的编码方式。当启用时,编码和解码会将代理符号(范围从 U+D800 到 U+DFFF)视为正常的字符。否则,遇到超出正常范围的字符,就会报错。
>>> "\ud800\udfff".encode("utf-8", errors="surrogatepass")
b'\xed\xa0\x80\xed\xbf\xbf'
>>> _.decode("utf-8", errors="surrogatepass")
'\ud800\udfff'
>>>
>>> "\ud800\udfff".encode("utf-8")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'utf-8' codec can't encode characters in position 0-1: surrogates not allowed
>>> b'\xed\xa0\x80\xed\xbf\xbf'.decode("utf-8")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xed in position 0: invalid continuation byte小节
总之,用哪个取决于你的场景,如果原始的有问题的字节无关紧要,你只是想摆脱错误,replace 和 ignore 是一个很好的选择;如果你需要保留它们以备后续处理,surrogate code 是正确的方法。[^3]
所以,UTF-8 全局编码模式开启后,也连带着启动了 surrogateescape 模式,目的就是为了出错时,保留原来的字节,以便适应用户的业务处理流。
如何开启
开启 UTF-8 模式非常简单,可以通过两种方式:
- 设置环境变量
PYTHONUTF8=1 - Use
-X utf8命令行参数
前者适合写入到系统环境变量,当然若是担心污染全局,也可以写在脚本中,随传随用。后者则是单次使用,临时更改。
操作截图
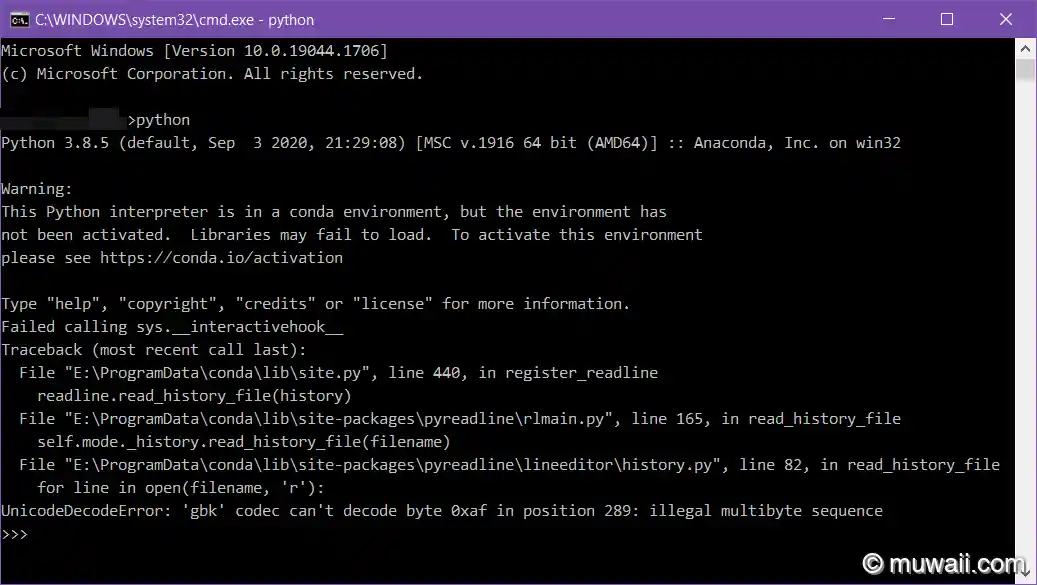
图 2: 字符编码有问题
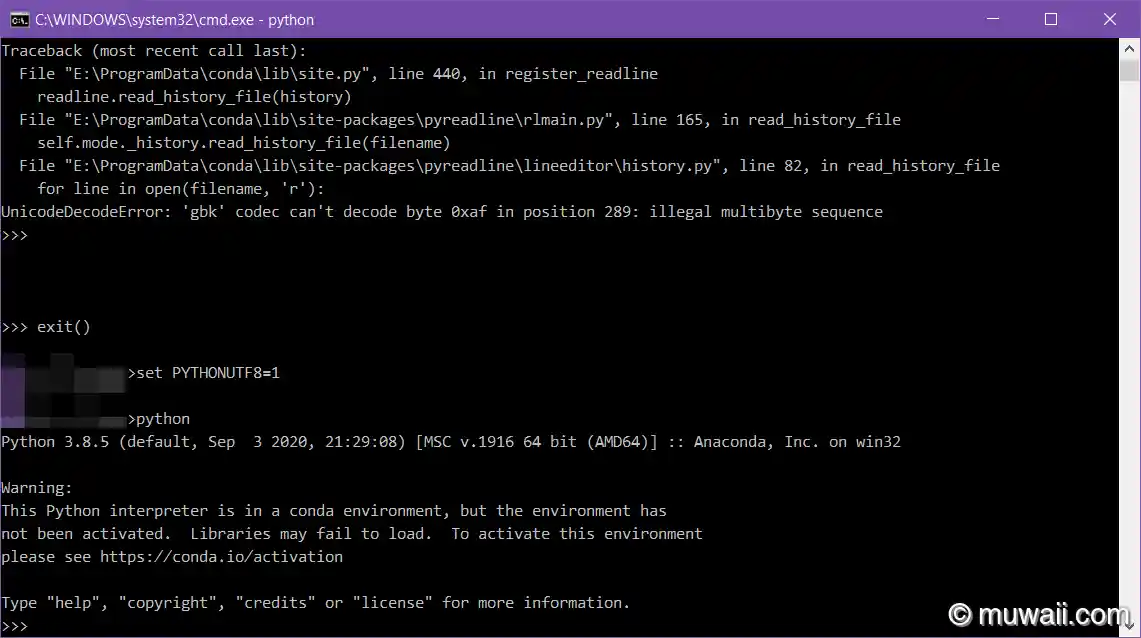
图 3: 启用 utf-8 模式
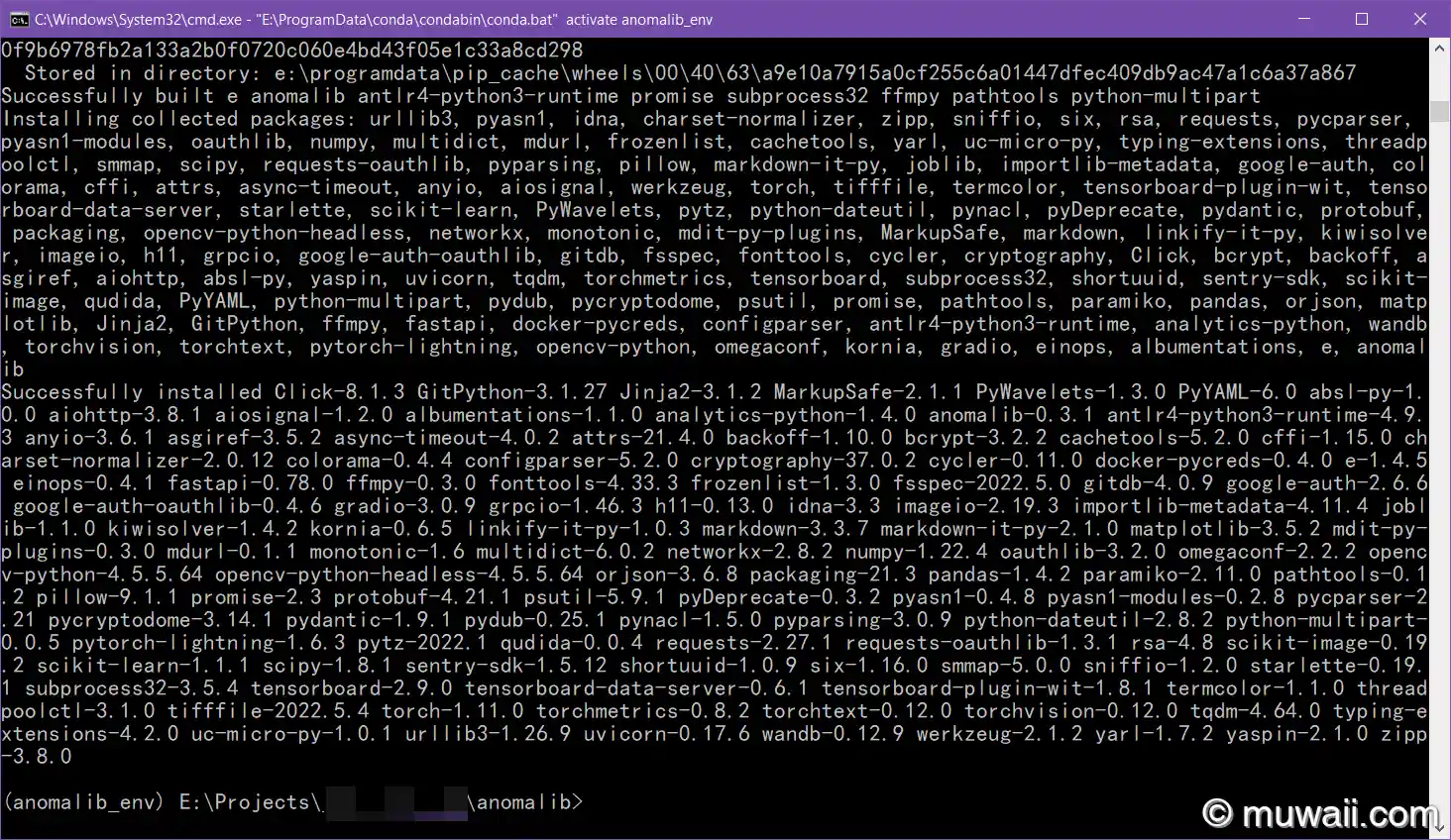
图 4: 成功安装 anomalib
总结
本文中,笔者尝试了几种可行的修改 Python 字符编码的方法,其中有临时的一次性命令行参数方案,也有长期的环境变量方案。读者可根据实际情况,自行选择合适的修改方式,摆脱 Windows 字符编码这一历史遗留大坑。
